In the early time of home computers, at the beginning of the 1980's, hard disks and even floppy disks were too expensive for home use. The cheapest way for storing large amounts of data was the cassette tape. Cassettes and tape recorders were affordable and available in almost any household.
In the early time of home computers, at the beginning of the 1980's, hard disks and even floppy disks were too expensive for home use. The cheapest way for storing large amounts of data was the cassette tape. Cassettes and tape recorders were affordable and available in almost any household.
In this blog article, I'm going to explain how the Sinclair ZX Spectrum stored programs on cassette tapes. Other home computers of that time, like the Commodore 64 or Amstrad CPC, worked in a similar fashion.
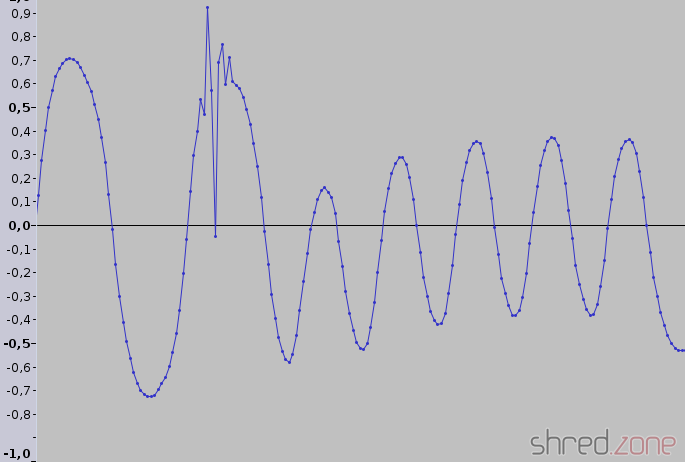
Cassette tapes were designed to store audio signals like voice or music, so the inventors of the home computers had to find a way to convert data to audio signals. The easiest way is to serialize the data to a bit stream of 1's and 0's, and generate a long rectangular wave cycle for "1" and a short rectangular wave cycle for "0". This is what the ZX Spectrum actually does!
A short wave cycle is generated by giving power to the audio output for 855 so called T-states, and then turning off the power for another 855 T-states. A "T-state" is the time of a single clock pulse of the Z80-A CPU. As the CPU of a classic ZX Spectrum is clocked with 3.5 MHz, a T-state has a duration of 286 ns. The duration of a short wave cycle is thus 489 µs, giving an audio frequency of about 2,045 Hz. The long wave cycle is just twice as long.
Due to all kind of filters in the analog audio path, the rectangular signal is smoothed to a sinusoidal signal when played back. A Schmitt trigger inside the ZX Spectrum's hardware converts the audio signal back to a rectangular shape. Since the audio signal can have different amplitudes or could even be inverted, the hardware only cares for signal edges, not for levels. All that the loader routine now has to do is to measure the duration of the pulses, regenerate the bit stream, and put the bytes back together.
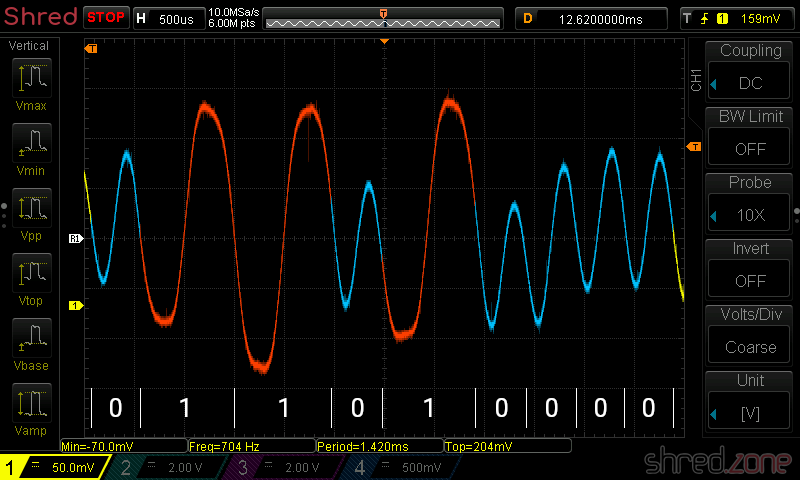
If you think that things cannot be that easy, you are right. 😄 The most difficult part for the loader is to find the start of the bit stream. If it is off by only one cycle (or even just a pulse), all the bytes are shifted by one bit, and the result is useless. All kind of noise on the tape makes it impossible to just wait for the signal to start, though.
For this reason, the recording starts with a leader signal, followed by a sync wave cycle, followed by the bit stream itself. The leader signal is just a continuous wave with a pulse length of 2,168 T-states, giving an 806 Hz tone that is displayed by red and cyan border colors on the TV. The sync wave cycle is a pulse of 667 T-States "on", followed by 735 T-states "off". After that, the actual data stream begins, which is displayed in blue and yellow border colors. When the last bit was transmitted, the data stream just ends.
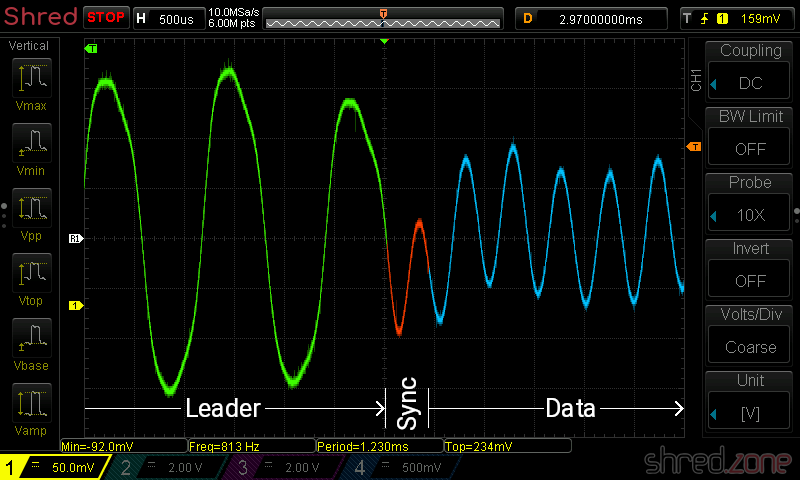
So when the ZX Spectrum loads a file from tape, it first waits for the 806 Hz leader signal. If it was detected for at least 317 ms, it waits for the sync pulses, then it starts reading the bit sequence until there is a timeout while waiting for the next pulse.
It is a very simple way to store data on tape. And still, it is surprisingly reliable. After 30 years, I could recover almost all files from my old cassette tapes. Some of them were of the cheapest brands I could get my hands on back in 1987.
The only disadvantage is that this method is very slow. With 489 µs for a "0" and 978 µs for a "1", saving just 48 KBytes of data can take up to 6 minutes, giving an average bit rate of 1,363 bps (yes, bits per second). If we were to save a single 3 MBytes mp3 file that way, it would take almost 5 hours (and 5 cassettes with 60 minutes recording time each).
Some commercial games used speed loaders and copy protections. Speed loaders just reduced the number of T-states for the pulses, which increased the bit rate. Some copy protections used a "clicking" leader tone, where the leader signal was interrupted before the minimal detection time of 317 ms was reached. The original loader routine could not synchronize to these kind of signals, so it was impossible to read those files into copy programs. Those protection measures could still be circumvented by copying directly from tape to tape, but this only worked a few times due to increasing audio noise.
In the next article, I will take a deeper look at the bit stream contents, and I will also explain where the dreaded "R Tape loading error" comes from.